Notes on GPU Programming
These notes are CUDA-specific
Table of Contents
Introduction
Programming using a GPU requires thinking in two memory spaces. There’s the host and the device. The host is powered by your CPU. Your CPU is very clever, has lots of tricks like speculative execution. The device is powered by the GPU. The GPU is not as clever, but it is built for problems that can be broken up into lots of parallel subproblems.
The types of problems best suited to CPUs look like this: $$ C_1 \to C_2 \to … \to C_n $$ Where \(C_k\) can’t be started until \(C_{k-1}\) is complete.
The types of problems best suited to GPUs look like this: $$ \begin{aligned} G_1 & \\ G_2 & \\ … \\ G_n \end{aligned} $$ Where \(G_i\) can be computed independently of all other \(G_j\)
The Mandelbrot set fractal has the property of being embarrasingly parallel. That’s another way of saying that each subproblem can be solved independently of all the other subproblems. The reason for this is that they depend only on the coordinates of a point in the complex plane. For the Mandelbrot set, you take a point $$z_0 = x + i y$$ and then send it to $$z_1 = z_0^2 + z_0$$
If that sequence \( {z_n} \) stays bounded, then it’s in the set, if it grows unbounded, then it’s outside the set. The boundary is where all the action is.
The basic model for programming a GPU is to break each problem up into blocks that can be executed independently on streaming multiprocessors (SM). The simple act of breaking the problem into blocks is the first step to exploiting parallelization. Each block also has up to 1024 threads that can run concurrently on that block.
Next you need to copy the memory from the host to the device: cudaMemcpy(hostPtr, devicePtr, size, cudaMemcpyHostToDevice)
And finally, use the special CUDA C syntax to launch your C function on the GPU device, kernel<<<numBlocks, numThreadsPerBlock>>>(arg1byVal, arg2byVal).
There are problems that are not embarassingly parallel, like training a neural network, but they can still benefit from parallelization on a GPU.
TODO: illustrate how backpropagation works and how it uses CUDA to accelerate the computation.
Blocks vs Threads
The CUDA programming model breaks everything up in to blocks and threads. Blocks contain many threads.
Each block has many threads. The GPU has many SMs (Streaming multiprocessors)
A block is assigned to an available SM, and it runs all the threads until it completes.
(image below taken from this official NVIDIA CUDA C programming guide)
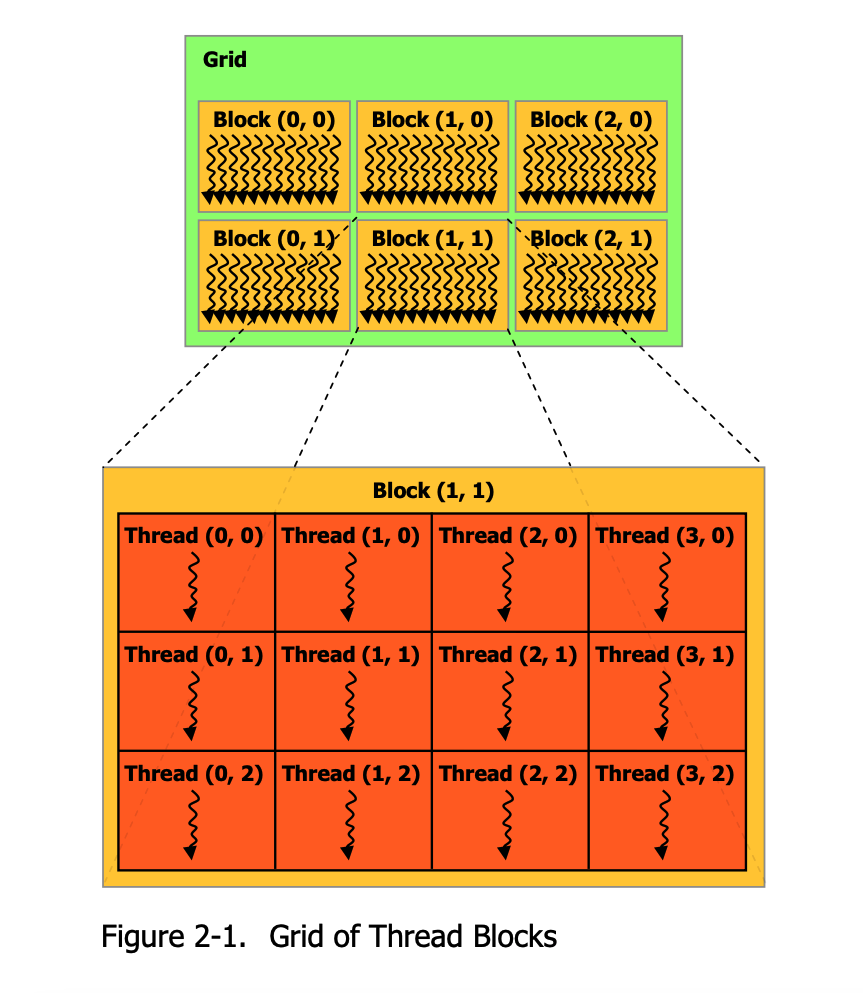
Different NVIDIA Cards have different numbers of SMs.