PCI Device passthrough on Harvester
I want to share something that I’ve been working on for the last three months. Release 1.1.0-rc3 now has working PCI passthrough. Any PCI device in your cluster can now be passed through the hypervisor directly to a VM. This allows virtual machines to directly control a device, like a GPU, without any expensive virtualization layer in the way.
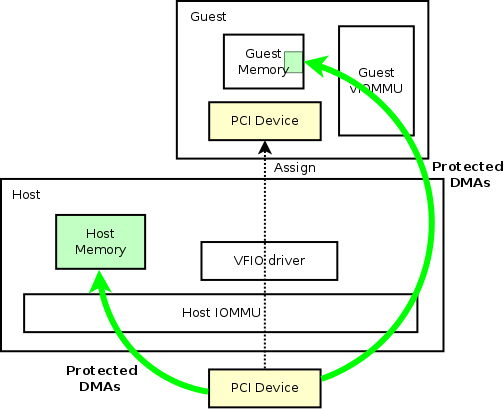
In the diagram above, the guest (VM) has direct memory access to the host’s memory for the device. This means that the hypervisor does not have to copy the data from the host to the guest, through a slow software layer.
PCI passthrough enables VMs to use GPUs to accelerate machine learning workloads, graphics rendering jobs, or anything that could benefit from fast, hardware-accelerated vector math. It also allows for high-volume networked workloads in virtual machines. Virtual machines have a software layer between them and the hardware. By default, high-bandwidth (e.g. 10Gbps) network interfaces can’t be maxxed out because the virtual ethernet device can act as a bottleneck.
How do you do PCI passthrough on Harvester?
You need to create a virtual machine, enable the devices for passthrough, and then attach them to your virtual machine. After that, the virtual machine owns the devices and can control them as if it were the host.
Below is a screen recording of me enabling PCI Devices for passthrough, attaching them to a VM, installing a linux distribution in the VM (with nvidia drivers), then compiling and running NVIDIA CUDA code and running multiple jobs on the GPU.
- 0:08 enabling passthrough on PCI devices
- 0:14 attach PCI devices to VM
- 0:38 installing NVIDIA drivers
- 1:32 running
nvidia-smito inspect the device from the vm - 2:19 compiling NVIDIA CUDA code to run on the device
- 3:00 running compiled CUDA code on device
- 4:19 running 10 parallel jobs on the device
If you are interested in trying this out, feel free to go to releases and install it. If you find any issues, please submit them here.
What is Harvester?
Harvester is an operating system for distributed computing. You can install it onto x86_64 computers and have them all join together in a cluster. This cluster is managed by an interface called Kubernetes. What makes Harvester special is the ability to manage VMs on your own hardware, using Kubernetes.
Harvester uses a stable Kubernetes distribution called RKE2. It also comes with a hypervisor called KubeVirt. KubeVirt lets you run VMs on a Kubernetes cluster, all managed through a single control plane.
The term “hyperconverged” means that storage and compute are part of the same machine. In practice this means that you can take a server or a PC and install Harvester on it. The software allows for other nodes to make use of resources on other machines.
How does passthrough work under the hood?
There are a few technologies that enabled this. The device uses DMA (Direct memory access) to copy data directly into memory without going through the CPU. Then the CPU itself uses an IOMMU (Input/Output memory management unit). The IOMMU allows the device to have a contiguous address space and then quickly map that to physical memory space, which might not be contiguous.
The Linux kernel needs to be booted with the intel_iommu=on and iommu=pt (pt for passthrough) kernel parameters.
After booting, you can enable passthrough on your PCI device by binding it’s PCI address to the vfio-pci driver.
Once a PCI device is enabled for passthrough, a VM can access the device and install it’s own drivers on it. In Harvester specifically, VMs are managed by KubeVirt, which uses a Pod running qemu. KubeVirt exposes an interface to attach host PCI Devices to the VM’s Pod.
The source code for the Kubernetes controller that manages the list of PCI devices and claims to those devices is here. That controller is now part of Harvester (as of release 1.1.0).
Sources:
- The passthrough diagram came from this great article: https://blog.sakuragawa.moe/vt-d-vfio-and-gpu-passthrough-virtualization-in-a-nutshell-rhel8/